行设计
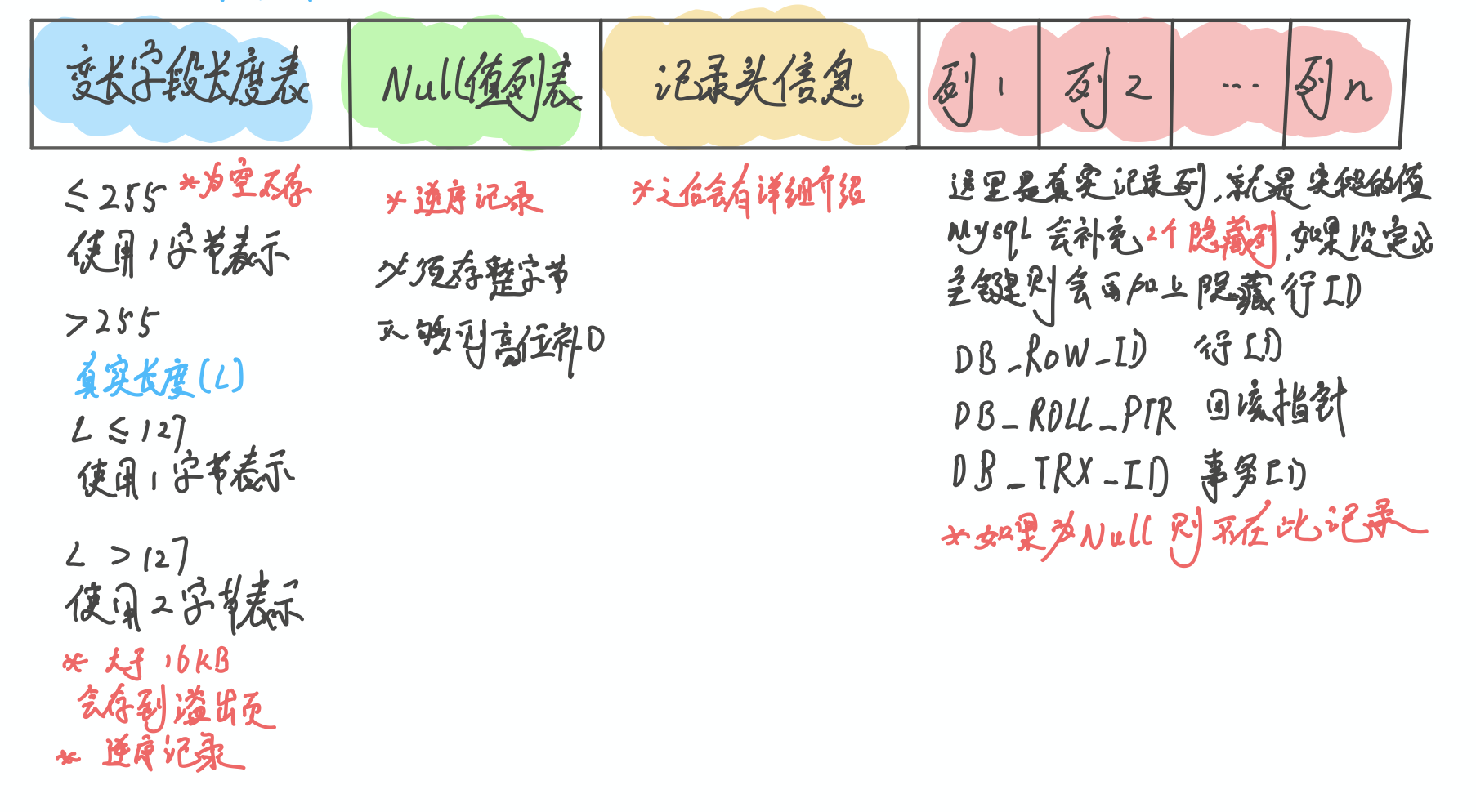
Varchar, text 等类型的变长字段的长度专门记录 Null 值专门记录, 不会在列信息中记录 有2个隐藏列, 分别是事务ID和回滚指针, 如果我们没有定义主键还会加上隐藏主键
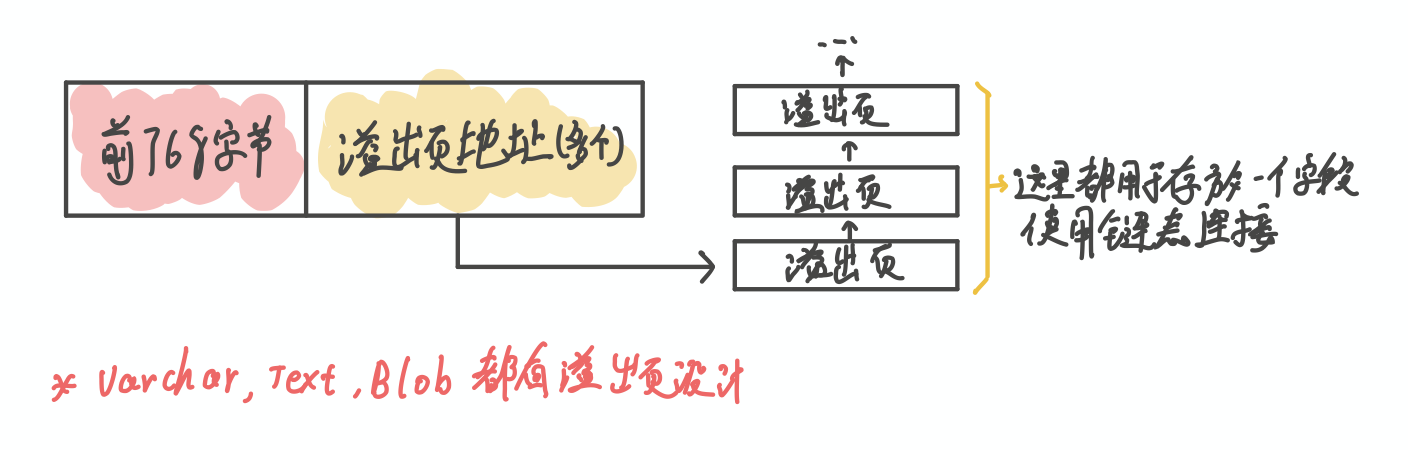
每页大小是16KB, 如果边长字段太大, 会将前768个字节存储在行中, 之后的数据存储到溢出页中.
页设计
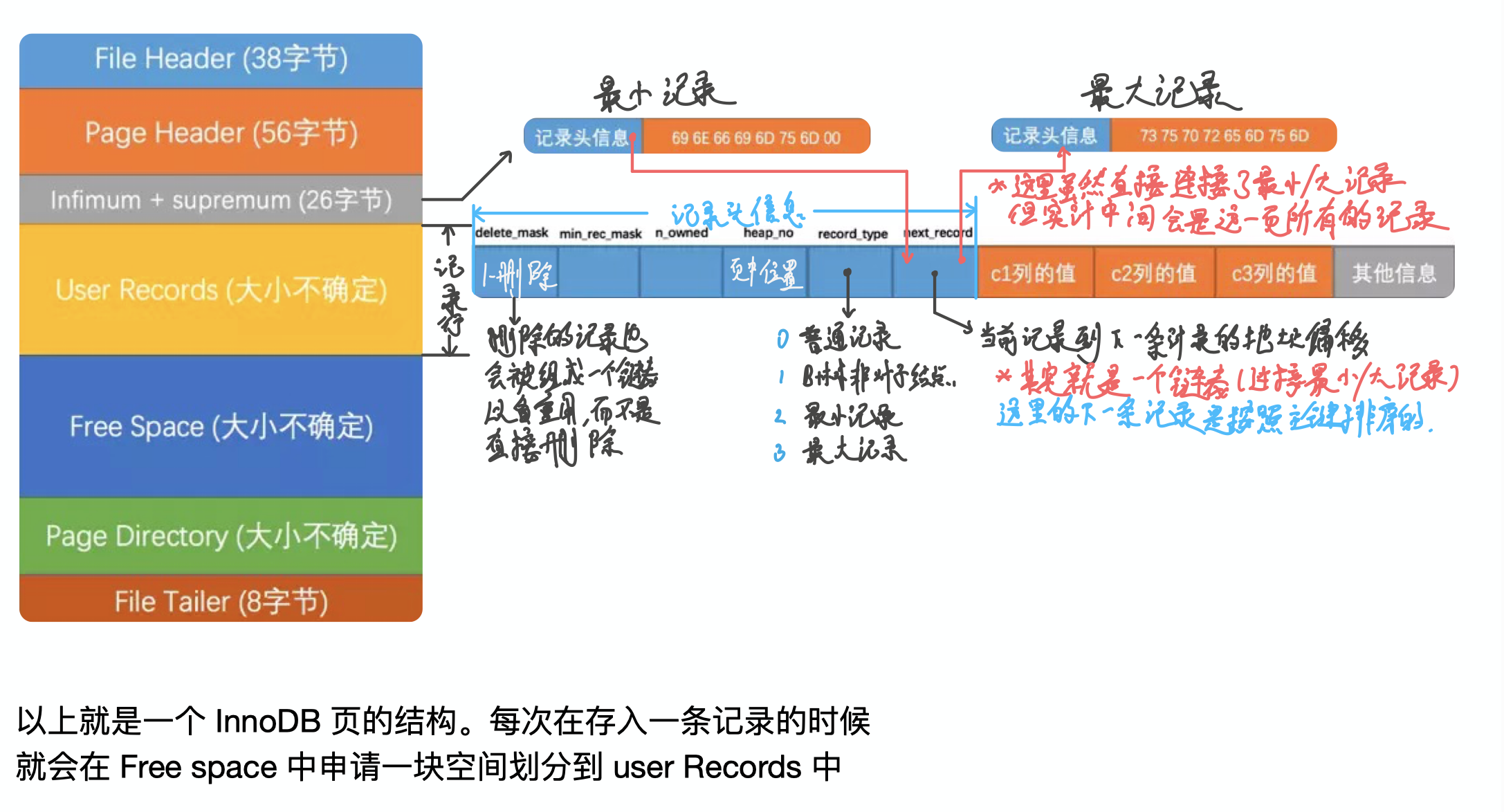
数据页结构如上图
- 可以看到删除最后并不会直接删除, 而是放到删除队列中.
- 并且除了我们的记录以外, Mysql还会给我们增加最小和最大2条记录.
- 记录格式通过 record_type 来设置
- 页中记录通过链表来连接
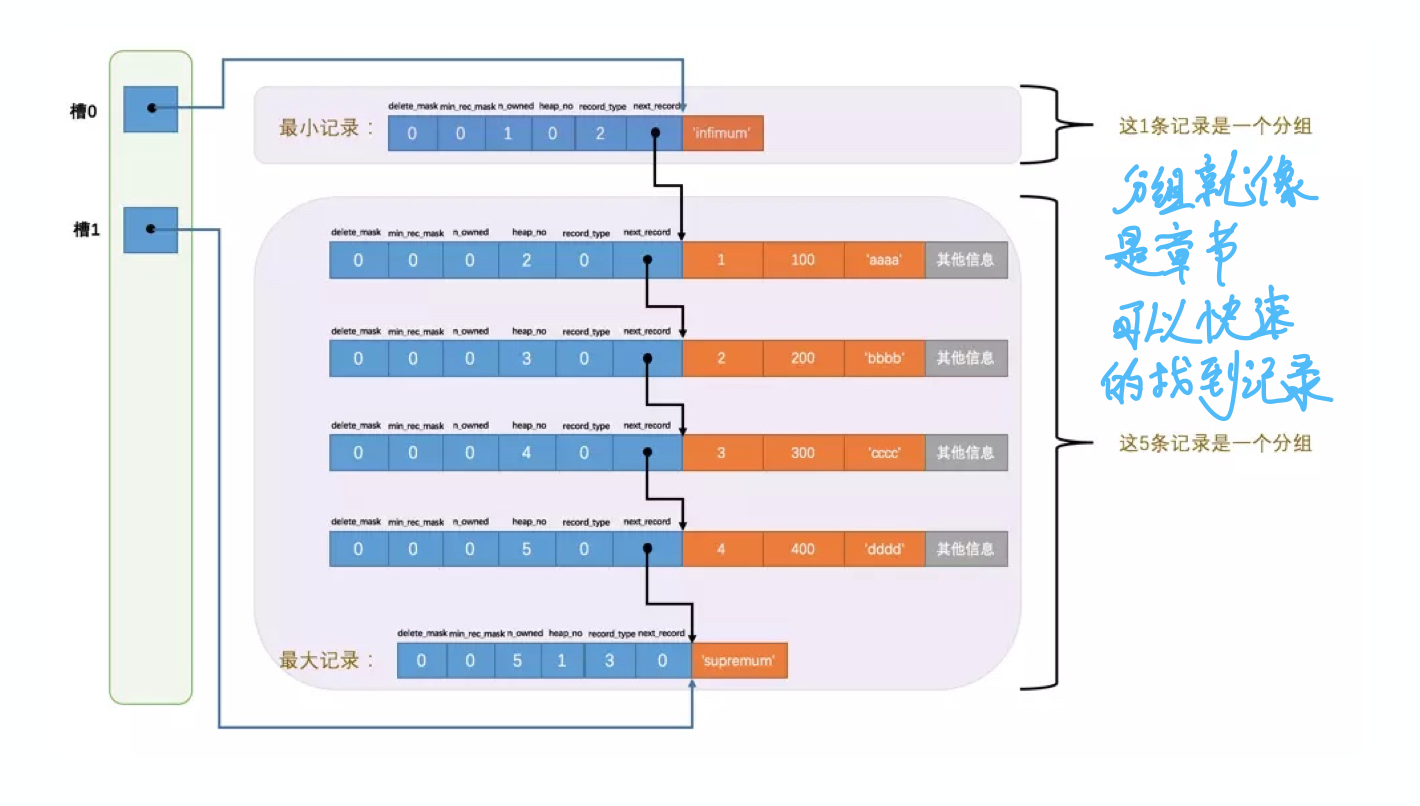
为了在页中快速导致记录, 还会增加页目录, 类似于hashMap的数组结构.
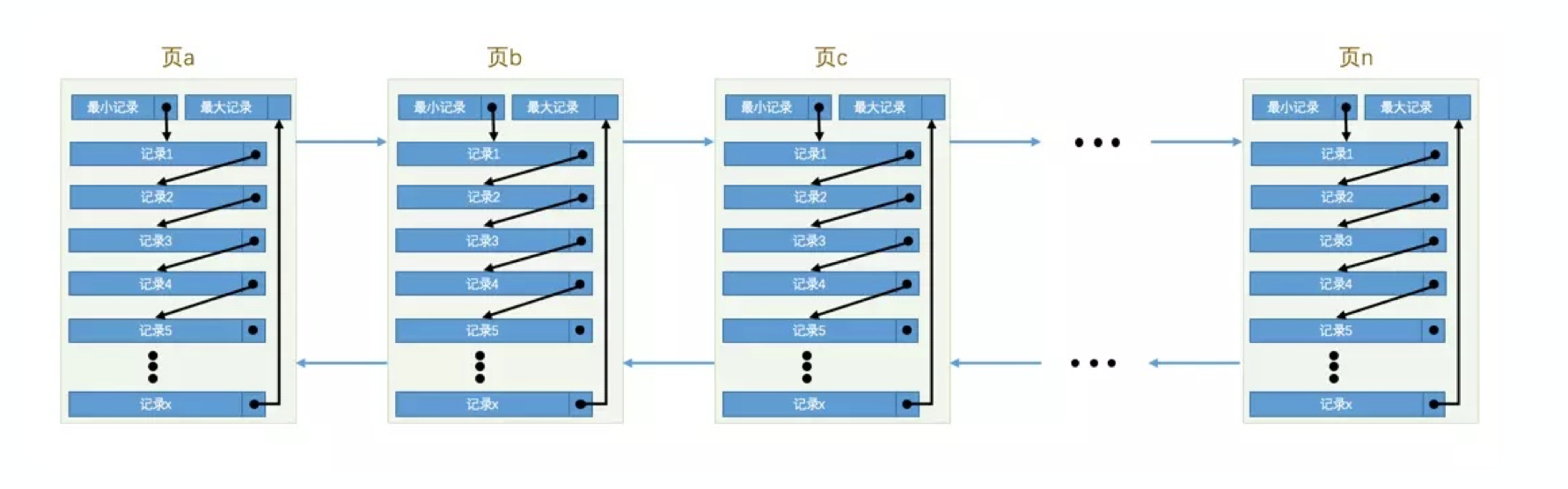
所以说, 页中连接大概就是这样的情况. 页之间是双向链表, 内部单向链表连接.
这样在查找的时候, 页之间可以通过双向链表遍历. 页内部先通过槽二分查询, 之后再单链表遍历
页设计与page cache
由于磁盘顺序读取的效率很高(不需要寻道时间,只需很少的旋转时间),因此对于具有局部性的程序来说,预读可以提高I/O效率。
预读的长度一般为页(page)的整倍数。页是计算机管理存储器的逻辑块,硬件及操作系统往往将主存和磁盘存储区分割为连续的大小相等的块,每个存储块称为一页(在许多操作系统中,页的大小通常为4k, 64位操作系统为8k),主存和磁盘以页为单位交换数据。当程序要读取的数据不在主存中时,会触发一个缺页异常,此时系统会向磁盘发出读盘信号,磁盘会找到数据的起始位置并向后连续读取一页或几页载入内存中,然后异常返回,程序继续运行。
B+ Tree
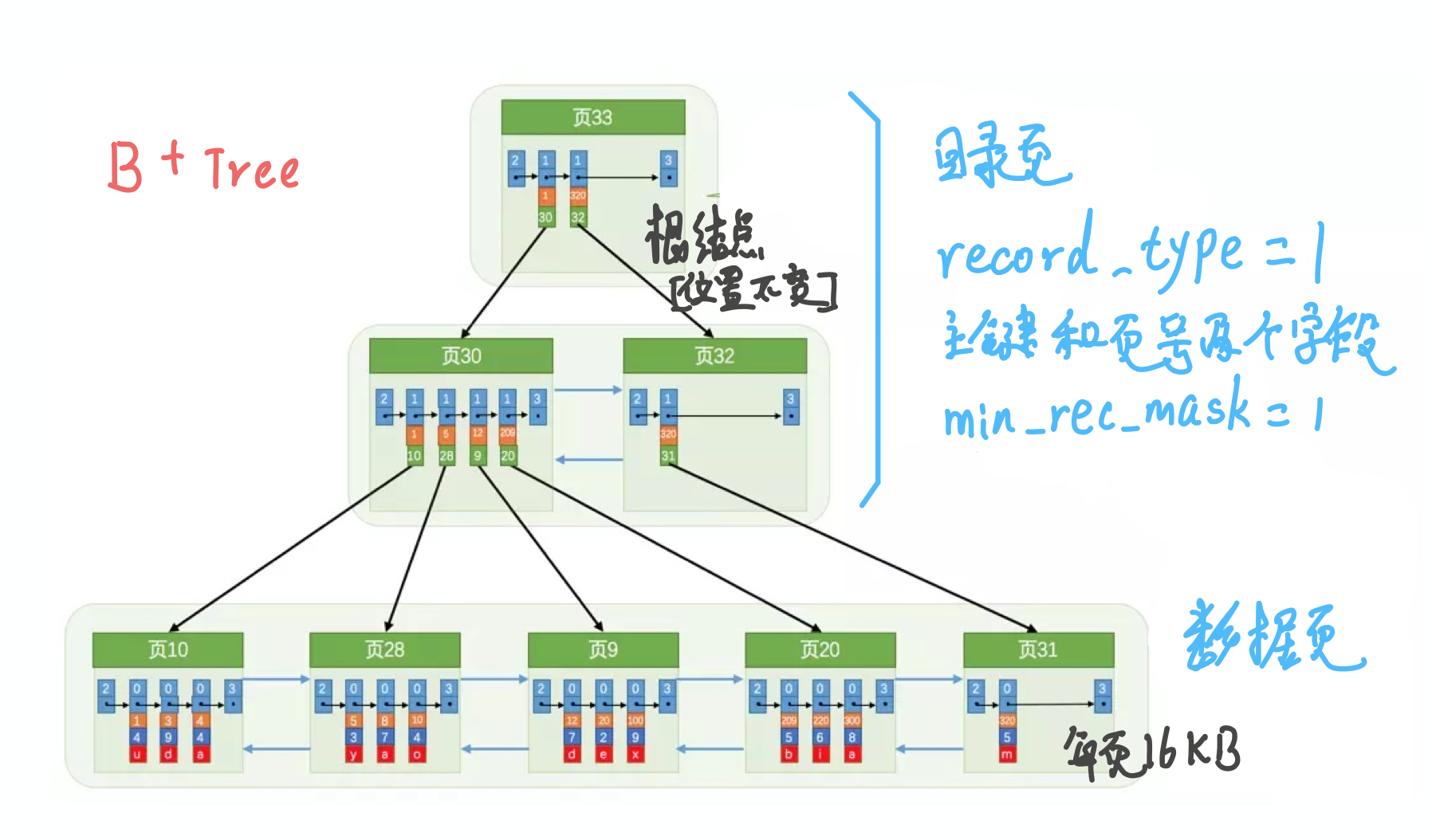
可以看到这就是B+Tree的结构图
- 索引即数据, 数据就存在聚簇索引的叶子节点
- 非叶子节点不存数据, 这样可以在每页大小固定(16KKB)的情况下, 存储更多的索引, 减小树的高度.
- 而且数据全在叶子节点, 可以大大增加区间查询效率
- 二级索引, 使用索引排序, 叶子节点不存全量数据, 存储索引列/主键ID/页号
- 联合索引 (a, b), 需要在a列相同的情况下才会按照b列排序.
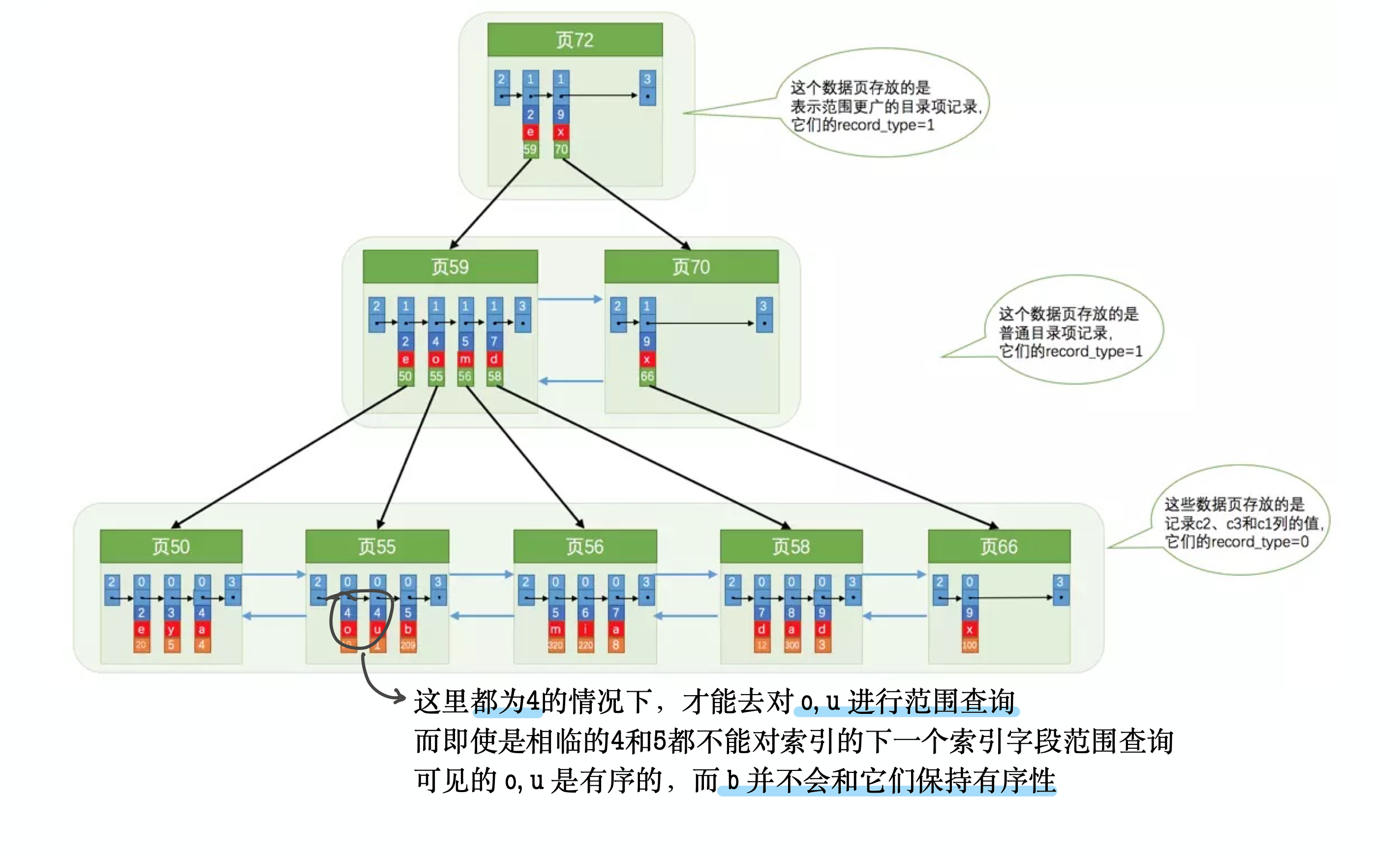
可以看出, 如果先按照前面的索引项排序, 之后的索引都无法使用. 联合索引会在范围查询后失效.
MyISAM

为什么InnoDB不在二级索引上存储物理地址, 还需要回表呢? 因为数据在主键索引的树上存储, 不像MyISAM数据另外存储, 树的结构调整物理地址就会变化, 会导致二级索引频繁修改.
读写分离,读库可以选择myisam
索引使用
最左一致性
Order by 如果不能用到索引就必须磁盘排序了 Group by 的字段如果和索引顺序相同, 则可以使用索引
索引应该尽量小, 但是如果使用字段前缀当做索引, 会导致无法排序
索引下推, 在有查询条件无法使用索引的时候本来需要回表查询整行信息过滤; 现在如果二级索引中有where的字段, 即使原来无法使用索引, 也可以在二级索引的叶子节点上进行过滤.
回表
查询完二级索引后, 拿到了主键值, 需要回表到主键索引上查询数据.
- 如果查询出的主键ID较为分散, 回表的时候就会读很多页, 全是随机IO. 很可能还不如全部查询效率高
- 如果查询的主键ID是连续的, 回表的消耗就会小很多. 顺序IO访问很快.
如果不想回表可以将查询字段全部做完索引, 这样的做法叫做覆盖索引.
表空间
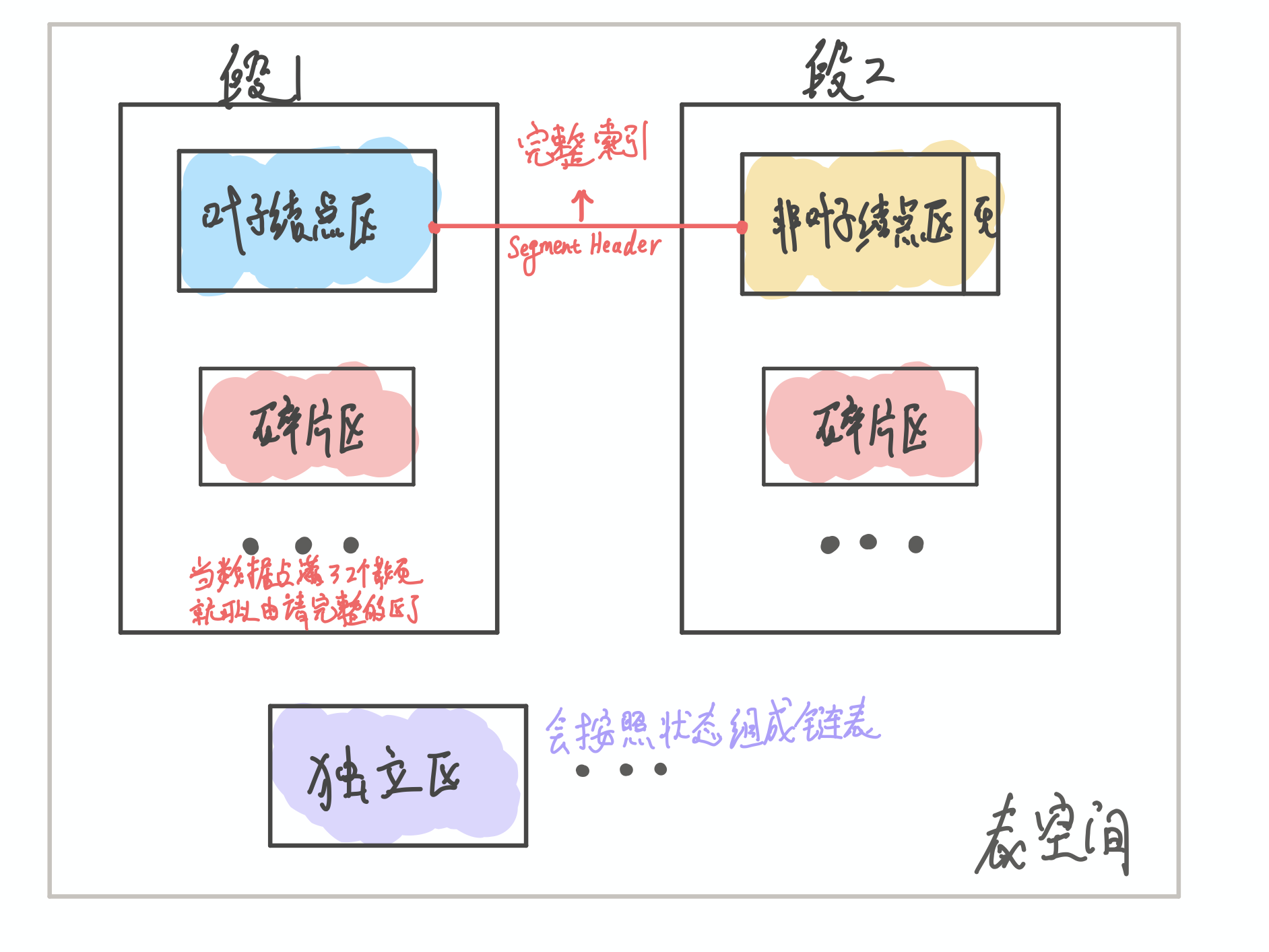
叶子节点其实和非叶子节点不存在一起, 因为顺序IO可以加快查询速度, 所以叶子节点是在一起的. 这样叶子节点集中在一个区中, 非叶子节点集中在另一个区. 而叶子节点和非叶子节点所在区的机会叫做段.