Java反射
首先提到反射是如何实现的, 首先从类加载阶段说起.
- 在加载阶段, 就把类信息加载到了方法区中
- 在解析阶段就可以把符号引用解析为直接引用(也可以不在类加载阶段完成)
- 在初始化阶段会对所有类对象进行初始化, 当然这一步也不一定要在类加载阶段完成. 但是触发类加载的条件有一项就是: 使用反射 API 对某个类进行反射调用时,初始化这个类.
现在拥有了 Method 实例所指向方法的具体地址。这时候,反射调用无非就是将传入的参数准备好,然后调用进入目标方法。知道了反射最基础的理论就可以深入研究一下反射了
1
2
3
4
5
6
7
8
9
10
11
public final class Method extends Executable {
...
public Object invoke(Object obj, Object... args) throws ... {
... // 权限检查
MethodAccessor ma = methodAccessor;
if (ma == null) {
ma = acquireMethodAccessor();
}
return ma.invoke(obj, args);
}
}
如果你查阅 Method.invoke 的源代码,那么你会发现,它实际上委派给 MethodAccessor 来处理。MethodAccessor 是一个接口,它有两个已有的具体实现:一个通过本地方法来实现反射调用,另一个则使用了委派模式。为了方便记忆,我便用“本地实现”和“委派实现”来指代这两者。 每个 Method 实例的第一次反射调用都会生成一个委派实现,它所委派的具体实现便是一个本地实现。而本地实现就是我们开头说过的拿到地址调用方法.
反射调用栈轨迹
1
2
3
4
5
6
7
8
9
10
11
public class Test {
public static void target(int i) {
new Exception("#" + i).printStackTrace();
}
public static void main(String[] args) throws Exception {
Class<?> klass = Class.forName("Test");
Method method = klass.getMethod("target", int.class);
method.invoke(null, 0);
}
}
以下是输出结果:
1
2
3
4
5
6
7
java.lang.Exception: #0
at com.qunar.silence.Test.target(Test.java:36)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at com.qunar.silence.Test.main(Test.java:42)
可以看到,反射调用先是调用了 Method.invoke,然后进入委派实现(DelegatingMethodAccessorImpl),再然后进入本地实现(NativeMethodAccessorImpl),最后到达目标方法。
这里你可能会疑问,为什么反射调用还要采取委派实现作为中间层?直接交给本地实现不可以么?
其实,Java 的反射调用机制还设立了另一种动态生成字节码的实现(下称动态实现),直接使用 invoke 指令来调用目标方法。之所以采用委派实现,便是为了能够在本地实现以及动态实现中切换。
1
2
3
4
5
6
7
8
9
// 动态实现的伪代码,这里只列举了关键的调用逻辑,其实它还包括调用者检测、参数检测的字节码。
package jdk.internal.reflect;
public class GeneratedMethodAccessor1 extends ... {
@Overrides
public Object invoke(Object obj, Object[] args) throws ... {
Test.target((int) args[0]);
return null;
}
}
动态实现和本地实现相比,其运行效率要快上 20 倍 。这是因为动态实现就和直接调用方法一样了而且无需经过 Java 到 C++ 再到 Java 的切换,但由于生成字节码十分耗时,仅调用一次的话,反而是本地实现要慢上 3 到 4 倍
考虑到许多反射调用仅会执行一次,Java 虚拟机设置了一个阈值 15(可以通过 -Dsun.reflect.inflationThreshold= 来调整),当某个反射调用的调用次数在 15 之下时,采用本地实现;当达到 15 时,便开始动态生成字节码,并将委派实现的委派对象切换至动态实现,这个过程我们称之为 Inflation。
反射调用的 Inflation 机制是可以通过参数(-Dsun.reflect.noInflation=true)来关闭的。这样一来,在反射调用一开始便会直接生成动态实现,而不会使用委派实现或者本地实现。
为什么反射会慢
这里做了一个实验, 循环调用一个空方法, 保证时间消耗都在反射上. 首先测试基准值, 直接调用平均100ms
TEST1
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
public static void target(int i) {
// 空方法
}
public static void main(String[] args) throws Exception {
Class<?> klass = Class.forName(“com.qunar.silence.IncokerTest”);
Method method = klass.getMethod(“target”, int.class);
long current = System.currentTimeMillis();
for (int i = 1; i <= 2_000_000_000; i++) {
if (i % 100_000_000 == 0) {
long temp = System.currentTimeMillis();
System.out.println(temp - current);
current = temp;
}
method.invoke(null, 0);
}
}
如果直接调用动态实现, 并且关闭权限校验. 平均执行时间是130ms, 可以大致让反射的速度达到正常执行的1.3倍. 而如果不直接调用动态实现, 则需要220ms, 大概是2.2倍
TEST2
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
public static void target(int i) {
// 空方法
}
public static void main(String[] args) throws Exception {
Class<?> klass = Class.forName(“com.qunar.silence.IncokerTest”);
Method method = klass.getMethod(“target”, int.class);
method.setAccessible(true); // 关闭权限检查
Object[] arg = new Object[1]; // 在循环外构造参数数组
arg[0] = 128;
long current = System.currentTimeMillis();
for (int i = 1; i <= 2_000_000_000; i++) {
if (i % 100_000_000 == 0) {
long temp = System.currentTimeMillis();
System.out.println(temp - current);
current = temp;
}
method.invoke(null, arg);
}
}
这里不能完成逃逸分析(在外部定义变量, 编译器无法确定其会不会中途被更改). 调用时间变成了300ms左右, 反射调用速度变成了3.0倍.
TEST3
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
public static void main(String[] args) throws Exception {
Class<?> klass = Class.forName(“com.qunar.silence.IncokerTest”);
Method method = klass.getMethod(“target”, int.class);
method.setAccessible(true); // 关闭权限检查
polluteProfile();
long current = System.currentTimeMillis();
for (int i = 1; i <= 2_000_000_000; i++) {
if (i % 100_000_000 == 0) {
long temp = System.currentTimeMillis();
System.out.println(temp - current);
current = temp;
}
method.invoke(null, 0);
}
}
如果我们通过反射调用多个实现, 编译器也无法记录, 无法使用方法内联优化 调用时间达到了惊人的860ms左右, 也就是达到了8.6倍.
至此我们可以大致得到结论, 不能逃逸分析大致会让我们比直接调用慢3倍. 而不能进行方法内联优化会慢8.6倍. 进而得出不能方法内联是反射很慢的主要原因
内联优化
在编译过程中遇到方法调用时,将目标方法的方法体纳入编译范围之中,并取代原方法调用的优化手段
也就是说, 可以再调用的时候不用再次执行而是将去变成外层执行方法的一部分, 直接访问就好
方法内联不仅可以消除调用本身带来的性能开销,还可以进一步触发更多的优化。因此,它可以算是编译优化里最为重要的一环。 以 getter/setter 为例,如果没有方法内联,在调用 getter/setter 时,程序需要保存当前方法的执行位置,创建并压入用于 getter/setter 的栈帧、访问字段、弹出栈帧,最后再恢复当前方法的执行。而当内联了对 getter/setter 的方法调用后,上述操作仅剩字段访问。
静态方法内联 为了说清楚这个问题, 我们先来一断代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
public static boolean flag = true;
public static int value0 = 0;
public static int value1 = 1;
public static int foo(int value) {
int result = bar(flag);
if (result != 0) {
return result;
} else {
return value;
}
}
public static int bar(boolean flag) {
return flag ? value0 : value1;
}
这里正常情况下我们是要调用2个方法的, 先调用foo方法, 之后再foo方法中调用bar方法. 以下是一个极简的IR图(左边的是foo方法, 右边的是bar方法):
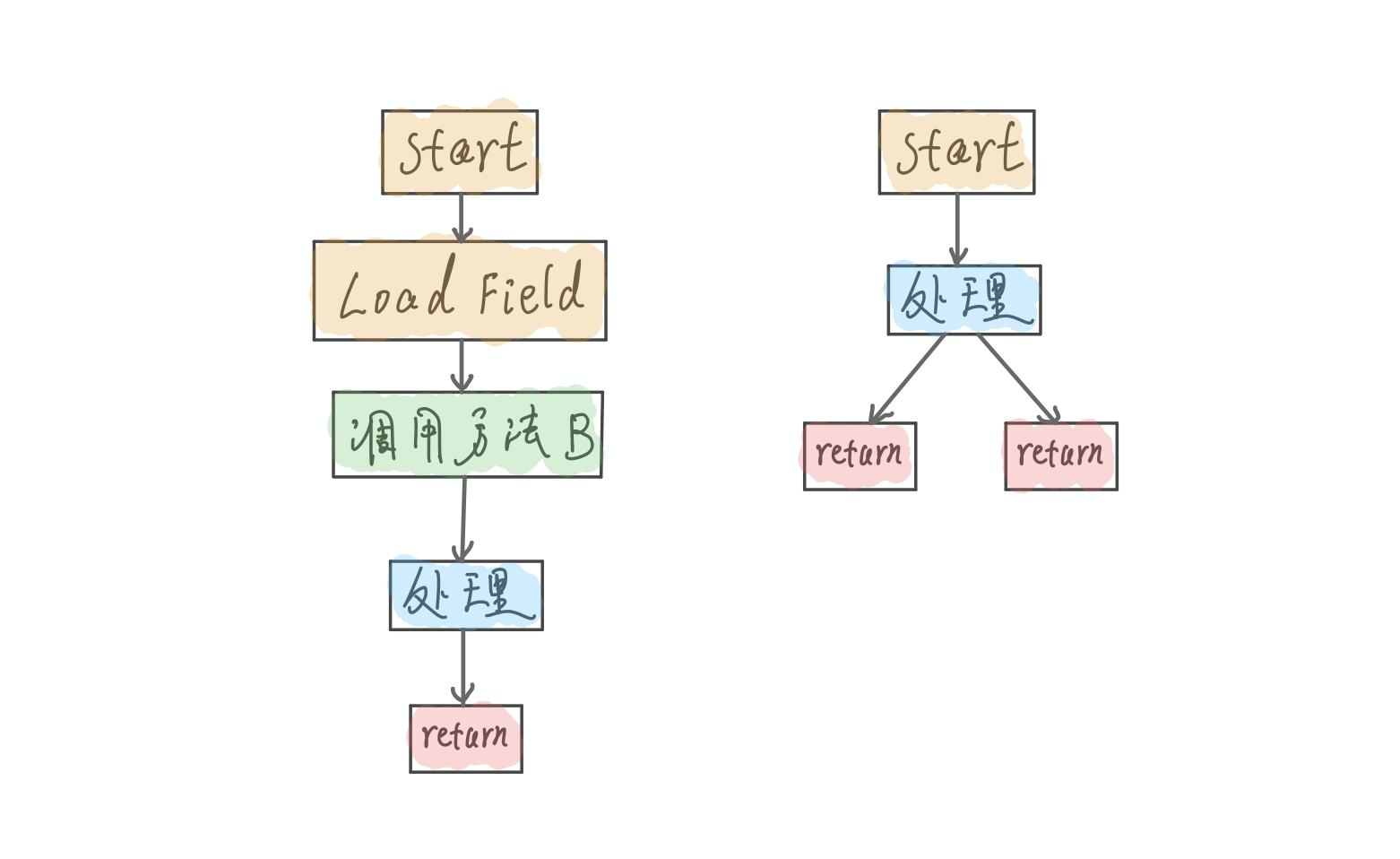
那如果要做内联优化呢, 其实就是把Bar方法嵌入到方法foo中. 以下是一个极简的IR图:
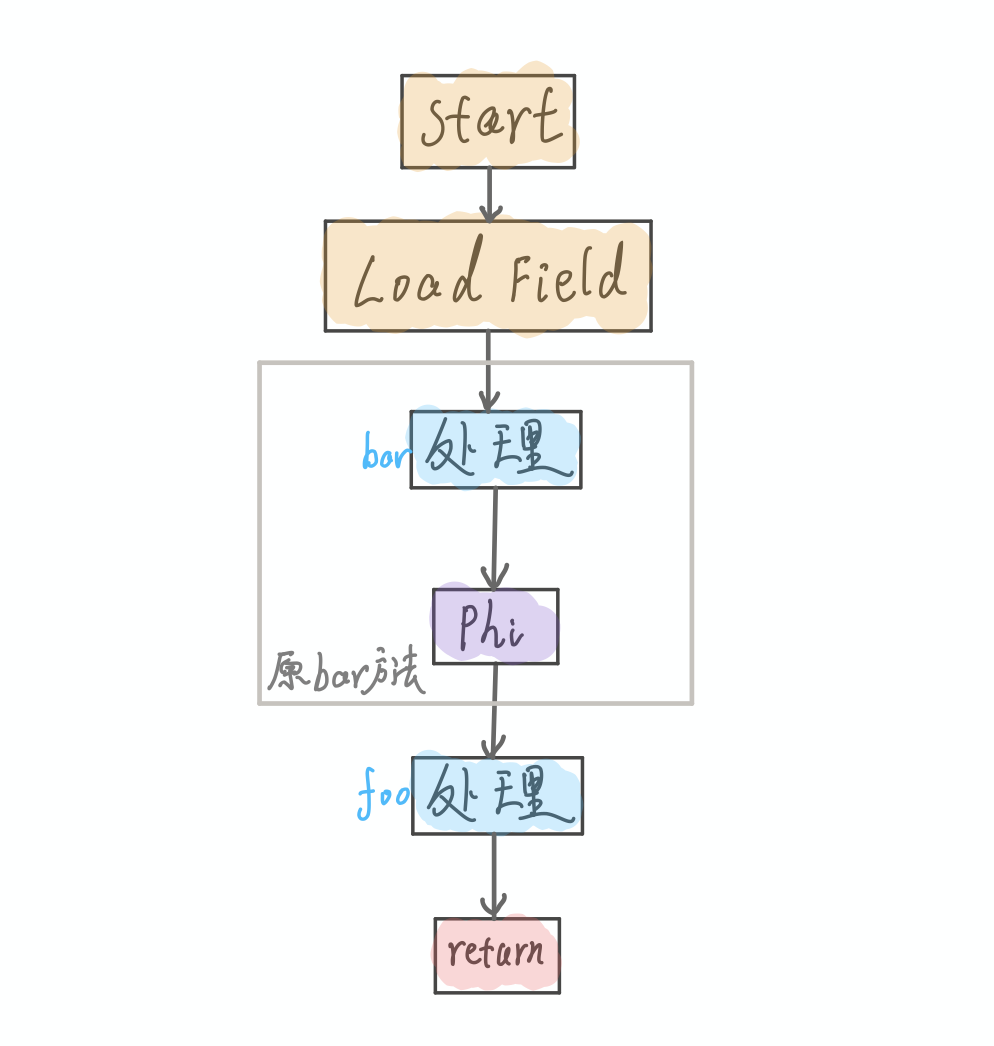
第一,被调用方法的传入参数节点,将被替换为调用者方法进行方法调用时所传入参数对应的节点。在我们的例子中,就是将 bar 方法图中的start节点替换为 foo 方法图中的LoadField节点。
第二,在调用者方法的 IR 图中,所有指向原方法调用节点的数据依赖将重新指向被调用方法的返回节点。如果被调用方法存在多个返回节点,则生成一个Phi 节点,将这些返回值聚合起来,并作为原方法调用节点的替换对象。
第三,如果被调用方法将抛出某种类型的异常,而调用者方法恰好有该异常类型的处理器,并且该异常处理器覆盖这一方法调用,那么即时编译器需要将被调用方法抛出异常的路径,与调用者方法的异常处理器相连接。
刚刚的代码除了内联外, 并没有做进一步的优化
反射修改final, 那final真的不可变吗? 我们改一下刚刚的例子, 我们将代码中的三个静态字段标记为 final
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
public final static boolean flag = true;
public final static int value0 = 0;
public final static int value1 = 1;
public static int foo(int value) {
int result = bar(flag);
if (result != 0) {
return result;
} else {
return value;
}
}
public static int bar(boolean flag) {
return flag ? value0 : value1;
}
Java 编译器(注意不是即时编译器)会将它们编译为常量值(ConstantValue),并且在字节码中直接使用这些常量值,而非读取静态字段。举例来说,bar 方法对应的字节码如下所示。
1
2
3
4
5
6
7
8
public static int bar(boolean);
Code:
0: iload_0
1: ifeq 8
4: iconst_0
5: goto 9
8: iconst_1
9: ireturn
在编译 foo 方法时,一旦即时编译器决定要内联对 bar 方法的调用,那么它会将调用 bar 方法所使用的参数,也就是常数 1,替换 bar 方法 IR 图中的参数。 经过死代码消除之后,bar 方法将直接返回常数 0,所需复制的 IR 图也只有常数 0 这么一个节点。该 IR 图可以进一步优化(死代码消除),并最终得到这张极为简单的 IR 图:
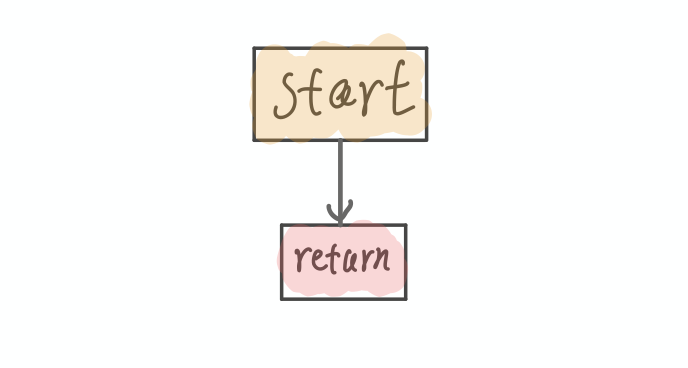
这样代码的运行过程就基本可以说被简化到只剩下一步返回了
说完刚刚的例子, 可以得到final直接被加载到了方法中, 根本不需要重新读取. 所以常量在 Java 编译过程中使用了内联优化, 即使反射修改值也是无效的
非静态方法的内联优化
对于需要动态绑定的虚方法调用来说,即时编译器则需要先对虚方法调用进行去虚化(devirtualize),即转换为一个或多个直接调用,然后才能进行方法内联。
- 完全去虚化是通过类型推导或者类层次分析(class hierarchy analysis),识别虚方法调用的唯一目标方法,从而将其转换为直接调用的一种优化手段。它的关键在于证明虚方法调用的目标方法是唯一的。
- 条件去虚化则是将虚方法调用转换为若干个类型测试以及直接调用的一种优化手段。它的关键在于找出需要进行比较的类型。它将借助 Java 虚拟机所收集的类型 Profile
方法内联的条件
方法内联能够触发更多的优化。通常而言,内联越多,生成代码的执行效率越高。然而,对于即时编译器来说,内联越多,编译时间也就越长,而程序达到峰值性能的时刻也将被推迟。 此外,内联越多也将导致生成的机器码越长。在 Java 虚拟机里,编译生成的机器码会被部署到 Code Cache 之中。这个 Code Cache 是有大小限制的(由 Java 虚拟机参数 -XX:ReservedCodeCacheSize 控制) 一般情况下即时编译器将根据方法调用指令所在的程序路径的热度,目标方法的调用次数及大小,以及当前 IR 图的大小来决定方法调用能否被内联。
逃逸分析
反射为什么慢, 除了没有内联之外, 另外一个原因是逃逸分析不再起效
这里先来看应该场景,我们知道,Java 中Iterable对象的 foreach 循环遍历是一个语法糖,Java 编译器会将该语法糖编译为调用Iterable对象的iterator方法,并用所返回的Iterator对象的hasNext以及next方法,来完成遍历。
1
2
3
4
5
6
7
public void forEach(ArrayList<Object> list, Consumer<Object> f) {
Iterator<Object> iter = list.iterator();
while (iter.hasNext()) {
Object obj = iter.next();
f.accept(obj);
}
}
这里我也列举了所涉及的ArrayList代码。我们可以看到,ArrayList.iterator方法将创建一个ArrayList$Itr实例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
public class ArrayList ... {
public Iterator<E> iterator() {
return new Itr();
}
private class Itr implements Iterator<E> {
int cursor; // index of next element to return
int lastRet = -1; // index of last element returned; -1 if no such
int expectedModCount = modCount;
...
public boolean hasNext() {
return cursor != size;
}
@SuppressWarnings("unchecked")
public E next() {
checkForComodification();
int i = cursor;
if (i >= size)
throw new NoSuchElementException();
Object[] elementData = ArrayList.this.elementData;
if (i >= elementData.length)
throw new ConcurrentModificationException();
cursor = i + 1;
return (E) elementData[lastRet = i];
}
...
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
}
}
那这里每次循环都需要创建对象是不是很占用内存呢? 是不是不应该使用foreach方法?
其实Java 虚拟机中的即时编译器可以将ArrayList.iterator方法中的实例创建操作给优化掉。不过,这需要方法内联以及逃逸分析的协作。
逃逸分析是什么
逃逸分析是“一种确定指针动态范围的静态分析,它可以分析在程序的哪些地方可以访问到指针” 在 Java 虚拟机的即时编译语境下,逃逸分析将判断新建的对象是否逃逸。即时编译器判断对象是否逃逸的依据,一是对象是否被存入堆中(静态字段或者堆中对象的实例字段),二是对象是否被传入未知代码中 前者很好理解:一旦对象被存入堆中,其他线程便能获得该对象的引用。即时编译器也因此无法追踪所有使用该对象的代码位置。 关于后者,由于 Java 虚拟机的即时编译器是以方法为单位的,对于方法中未被内联的方法调用,即时编译器会将其当成未知代码,毕竟它无法确认该方法调用会不会将调用者或所传入的参数存储至堆中。因此,我们可以认为方法调用的调用者以及参数是逃逸的。
那什么对象是没有逃逸的呢? 例如下面的代码:
1
2
3
4
5
6
public static String craeteStringBuffer(String s1, String s2) {
StringBuffer sb = new StringBuffer();
sb.append(s1);
sb.append(s2);
return sb.toString();
}
Sb是一个方法内部变量,上述代码中并没有将他直接返回,这样这个StringBuffer有不会被其他方法所改变,这样它的作用域就只是在方法内部。我们就可以说这个变量并没有逃逸到方法外部。
通常来说,即时编译器里的逃逸分析是放在方法内联之后的,以便消除这些“未知代码”入口
也就是说逃逸分析就是帮我们把希望优化代码所需的所有资源都先找到, 并且加载出来
基于逃逸分析的优化
即时编译器可以根据逃逸分析的结果进行诸如锁消除、栈上分配以及标量替换的优化 我们先来看一下锁消除。如果即时编译器能够证明锁对象不逃逸,那么对该锁对象的加锁、解锁操作没有意义。这是因为其他线程并不能获得该锁对象,因此也不可能对其进行加锁。在这种情况下,即时编译器可以消除对该不逃逸锁对象的加锁、解锁操作。 如果逃逸分析能够证明某些新建的对象不逃逸,那么 Java 虚拟机完全可以将其分配至栈上,并且在 new 语句所在的方法退出时,通过弹出当前方法的栈桢来自动回收所分配的内存空间。这样一来,我们便无须借助垃圾回收器来处理不再被引用的对象。 不过,由于实现起来需要更改大量假设了“对象只能堆分配”的代码,因此 HotSpot 虚拟机并没有采用栈上分配,而是使用了标量替换这么一项技术。 所谓的标量,就是仅能存储一个值的变量,比如 Java 代码中的局部变量。与之相反,聚合量则可能同时存储多个值,其中一个典型的例子便是 Java 对象。 标量替换这项优化技术,可以看成将原本对对象的字段的访问,替换为一个个局部变量的访问。举例来说,前面经过内联之后的 forEach 代码可以被转换为如下代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
public void forEach(ArrayList<Object> list, Consumer<Object> f) {
// Itr iter = new Itr; // 经过标量替换后该分配无意义,可以被优化掉
int cursor = 0; // 标量替换
int lastRet = -1; // 标量替换
int expectedModCount = list.modCount; // 标量替换
while (cursor < list.size) {
if (list.modCount != expectedModCount)
throw new ConcurrentModificationException();
int i = cursor;
if (i >= list.size)
throw new NoSuchElementException();
Object[] elementData = list.elementData;
if (i >= elementData.length)
throw new ConcurrentModificationException();
cursor = i + 1;
lastRet = i;
Object obj = elementData[i];
f.accept(obj);
}
}
被标量替换的字段可以存储在栈上,也可以直接存储在寄存器中。而该对象的对象头信息则直接消失了,不再被保存至内存之中。 而且由于该对象没有被实际分配,因此和栈上分配一样,它同样可以减轻垃圾回收的压力。与栈上分配相比,它对字段的内存连续性不做要求,而且,这些字段甚至可以直接在寄存器中维护,无须浪费任何内存空间。
对于逃逸分析可以参考: 求你了,别再说Java对象都是在堆内存上分配空间的了! - 掘金
逃逸分析的不成熟 其根本原因就是无法保证逃逸分析的性能消耗一定能高于他的消耗。虽然经过逃逸分析可以做标量替换、栈上分配、和锁消除。但是逃逸分析自身也是需要进行一系列复杂的分析的,这其实也是一个相对耗时的过程。 一个极端的例子,就是经过逃逸分析之后,发现没有一个对象是不逃逸的。那这个逃逸分析的过程就白白浪费掉了。